This post will bring you through my motivations and process for training musicgen-songstarter-v0.2, a fine-tuned MusicGen model that produces useful samples for music producers.
This is not a research paper. However, much like a research paper, there is a bit of a long winded background in the beginning here to give you some context. Skip to the plan if you want to get straight to the technical details.
If you find this post interesting, please consider supporting my work by:
- Giving the model a like on Hugging Face here ❤️
- Giving the source code of singing-songstarter a star ⭐
- Following me on Twitter 🐦
- Following me on GitHub 🐙
- Sharing this post with your friends/enemies 📤
My Background in Music
Before I got into programming, I used to spend my free time producing music. I spent countless hours in middle school downloading various software onto the family computer and infecting it with viruses (sorry Mom!). Nobody I knew at school was into that sort of thing, so I had to go online to find folks like me who were tinkering with music production. Once I found a few friends via [what I imagine were] Soundcloud DMs, we formed a Facebook group to chat, collaborate, share our music, and ask technical questions.
This was one of my first real experiences with an online, collaborative community. It was such a beautiful thing. Through collaborating with folks in this group, I was “signed” to a couple record labels and released tracks on Beatport. In hindsight, the “labels” were probably just some dudes in their basement taking advantage of kids like me, but it was still fun to get my music out there.
As time went on, I got less interested in EDM and more into instrumental hip-hop/experimental music. I started producing, mixing, and mastering for local artist friends of mine. I stopped trying to market my music and just made music for myself, sometimes sharing links with friends and family. Felt more fun this way. At some point along the way, I started ramping up learning programming and ML, and basically stopped making music altogether. Pretty lame!
Here’s of my favorite tracks I made (Yes, I realize how wild it is to plug my Soundcloud in a ML blogpost 😂)
AI music research + the MusicGen weights release
I may have put my DJing career on the backburner, but over the years I’ve tried to keep up with the intersection of AI and music. When I saw the papers for MuLan/MusicLM, I started to get really excited. MusicLM showed a LOT of potential. But of course, Google chose not to release the weights. 😭
A year later, in Jan 2024, Meta dropped the code AND weights for MusicGen. This model was a bit simpler in architecture compared to MusicLM - it takes audio and tokenizes it with Encodec, then feeds it to a transformer. They showed how you could control the generation by conditioning on text, melody, metadata, etc. The hype was real!! 🔥
With the excitement also came some minor frustrations…it was exciting because it was a huge step forward in the field of AI music generation - and the weights were open. Frustrating because the Encodec model used to train the larger variants of MusicGen was for 32khz mono audio. A 44.1k/48k stereo MusicGen would have earth shattering for the AI community. Instead, they teased us a bit by releasing a 48k stereo Encodec, but made it frustrating to use in their training codebase, so nobody could practically train a new MusicGen checkpoint with it (if I’m mistaken about this, please let me know and I’ll revise!). Even if you could, you’d need a bunch of compute to make it happen.
After some time, Meta released “stereo” variants of the MusicGen models with a bit of a hack to interleave codebooks for left and right channels - still using the mono Encodec under the hood. I’ve heard these described as being “too stereo”, which I tend to agree with. Gripes aside, these stereo models are still INCREDIBLE and I am so grateful for their release. 🙏
MusicGen - will it fine-tune?
A few months after the release of MusicGen, when there were still just mono models available, I started wondering: how hard it would be to fine-tune this? Just like with any large pretrained model, you often get the best results for your use case by fine-tuning on your own data. I had a hunch that fine-tuning MusicGen on a dataset of music samples could produce some really cool results.
My first idea was to fine-tune on specific artists. Basically “generate a song that sounds like <artist> made it”. My intuition was that for this to work, the style of the songs would have to be distinct. So, I started tinkering with the audiocraft codebase, trying to figure out how the training code worked, how to format the data, etc. For me, the codebase is a bit hard to follow. Nested Hydra configs, a PyTorch trainer suite, flashy, that lives in a different github repo, an experiment manager, dora, that also lives in a different repo. It’s a lot to take in!!
Initial experiments with fine-tuning on artists
After some exploration, I figured out how to get training running using their codebase, and prepared a dataset of samples from a few artists and started training for the text-to-music task, starting from the musicgen-small checkpoint as that was the largest model I could fit on a Google Colab A100 40gb GPU. For the dataset, since I didn’t have text captions for the music, I set the captions to be the same every time: “an electronic instrumental in the style of <artist>”.
The results were…okay. I had to generate a lot of samples to get some good ones out…most were riddled with artifacts/noise/strange sounds/silence. I also was plagued by a sneaking suspicion that the model was overfitting and just regenerating existing tracks. Here are some clips from the first model I trained, where I used a dataset of songs by Monte Booker:
| Text Prompt | Output |
|---|---|
| jazz trumpet over a hip hop beat in the style of montebooker | |
| reggae chords over a hip hop beat in the style of montebooker |
Aha moment 💡
These results felt promising to me! So, I went over to Monte Booker’s discord and shared the results, asking for feedback. Immediately, folks started taking the samples I shared and remixed them - chopping them up, adding better drums, etc.
This made something click for me…why not make the outputs even more usable for producers? Instead of generating full tracks like I was doing, why not generate loops like you’d buy from Splice? This way, I’m not making an “AI version of the artist”, but rather creating a tool that music producers can use creatively. If done correctly, I’d get rid of most of the ethical concerns I was having while also building a more unique project.
This would be like the new age of sampling! 🤯
The plan
Data
If you’re not familiar - Splice is a app most music producers use. It lets you buy samples (drum sounds, melody loops, etc) that you can use in your songs. All these years, I’ve been subscribed to Splice but not producing much music. As a result, I had accumulated a lot of credits. So, my plan was to download a bunch of loops from Splice and use those to train a new model.
Downloading the data
Nothing too fancy here. I sat at my computer and listened to samples for a long time - listening and purchasing samples carefully. Some key notes from this process:
- I wanted to stick with samples that matched my taste. I went for hip hop/rap/electronic melodic loops, as well as some soul/jazz samples.
- I had to be careful not to download samples that were too similar to each other. Often times sample packs had complimentary samples that were too similar to each other. I wanted to make sure the model was learning a wide variety of sounds.
- I wanted samples to be 15-30s long (note MusicGen was trained on 30s samples).
- I wanted to avoid drums altogether so the model would un-learn to generate drums.
For the songstarter-v0.1, I used ~600 samples. For songstarter-v0.2, I used around 1700-1800 samples - about 7-8 hours of audio altogether.
Data prep
I prepared metadata JSON files following the audiocraft repo’s examples. I set the tags to be the “description”, formatting it like:
{tag_1}, {tag_1}, ..., {tag_n}, {key}, {bpm} bpmFor example:
hip hop, soul, piano, chords, jazz, neo jazz, G# minor, 140 bpmI included bpm and key attributes in the audiocraft JSON metadata files as well (which, looking back, means they were included twice in the input to the model sometimes). I also included the genre if it was available. I left mood and instruments blank.
Training
Audiocraft Woes + rewriting training w/ PyTorch Lightning
Once I felt I had a good dataset to start training medium/large models, I would spin up a VM on Lambda, and try to start training with the original training code from audiocraft. Unfortunately, in addition to the codebase being hard to navigate (which I attribute to the nested Hydra configs), I ran into a lot of issues with training itself.
Specifically, there were bugs when using FSDP that caused deadlocks. When you’re spending your own personal $$$, you want the training to be as efficient as possible, so not being able to use FSDP reliably was an issue.
So, I rewrote the training loop with PyTorch Lightning, as its a nice tool to use when you’re trying to focus on the model rather than the training loop. This worked. The one major headache my implementation causes is that the checkpoints are saved different than the original audiocraft checkpoints…but at least it works!
As a quick aside, I think some of my issues with FSDP in
audiocraftmay have been H100 specific. There are some lingering issues on their GitHub about it. My implementation also had some issues on H100 that I am not 100% sure are resolved. Had limited time to debug because every hour spent not training was ~$30. I actually ended up burning most of the credits Lambda gave me for this project just on one 12 hour session debugging FSDP issues on an 8xH100. 😭 The final training run was done on 8xA100 40GB.
The training code I used is available via my fork of the audiocraft repo here. Note I did not add the validation loop here - I found I was evaluating the model by generating samples and listening to them, so I didn’t bother with it. Again, I was doing most of this on my own time, so I was moving quickly. Don’t judge me, k? 😅
Training details
I don’t have the exact details for v0.1, which was a medium melody model, so we’ll just discuss musicgen-songstarter-v0.2.
v0.2 was fine-tuned on top of facebook/musicgen-stereo-melody-large on a Lambda Labs 8xA100 40gb instance for 10k steps, which took about 6 hours. With FSDP, I could safely fit a batch size of 5 per device, so that’s what I used (meaning global batch size of 40). I reduced the minimum segment duration to 15s (from the base model’s 30s). The code is available here, but is undocumented as of now.
I tried a few different combos of batch size / segment duration to find what made sense for me. In the end, even though we trained on smaller samples, the model can still generate longer samples - at the cost (or benefit, depending who you ask) of the fact they are usually looping.
Training Metrics
You can find the training metrics on WandB. Here’s a link to the run with all the metrics and hyperparameters. Metrics themselves aren’t too useful, but figured I’d make them available.
Results
I don’t have any quantitative results to show here. I figured it would be unfair to eval against MusicCaps as an eval, since my model is for a more specific use case. Its prompts weren’t natural language, but instead lists of tags (which also applies to my comparisons below). Instead, I encourage you to hear what it can do!
Prompt + Melody ➡️ Music
We fine-tuned on top of a melody model. The base model, facebook/musicgen-stereo-melody-large, was trained to both be able to generate audio that sounds like a desired text prompt as well as generate audio that matches a desired melody. When we fine-tuned on top of the model, we did so for text-to-music only. However, we get the melody conditioning for free! Here’s a couple examples showing what the model sounds like. For clarity, I’ve included outputs from the base model as well. For both, I generated 4 samples and picked the best one.
| Audio Prompt | Text Prompt | musicgen-songstarter-v0.2 | musicgen-stereo-melody-large |
|---|---|---|---|
| trap, synthesizer, songstarters, dark, G# minor, 140 bpm | |||
| acoustic, guitar, melody, trap, D minor, 90 bpm |
Sing an Idea + Prompt ➡️ Music
Something I couldn’t shake after hearing the results above was: “it would be so much cooler if I could just hum the melody”.
I can’t tell you how many times I’ve sat down to produce music and just stared at my DAW, not knowing where to start. I am not good enough at piano to just sit down and let ideas flow - I’m a classically trained trombone player. It would be kinda whack to see me whip out a trombone in the middle of a session 😂. Instead, I usually start by humming a melody, then try to find the notes on the piano roll.
I struggled with this for a bit until I realized I was just being stupid - the solution was right in front of me. Under the hood, when MusicGen does melody conditioning, it runs stem separation on the audio prompt to remove vocals, as they can make it harder to find a stable signal for conditioning. By simply removing this step, we can prompt with vocals directly! 🔥
💡 Fun fact - did you know that Michael Jackson used to sing his melodies into a tape recorder for his producers? Here’s his demo tape for Beat It. Imagine if Michael could have produced his own tracks using just his voice! 🤯
Now, unless you’ve got a voice like Michael’s, you likely don’t sing with perfect pitch. We reintroduce the problem that stem separation tried to solve. If your vocals are off pitch, or have fast vibrato, the model will have a hard time finding a stable signal to condition against. To try and mitigate that, you can run pitch correction on your vocals before feeding them through to the patched model. I used some modified code from this AWESOME blogpost by @wilczek_jan to do this.
Here, you can listen to the difference between my original and pitch corrected vocals.
| Original | Pitch Corrected |
|---|---|
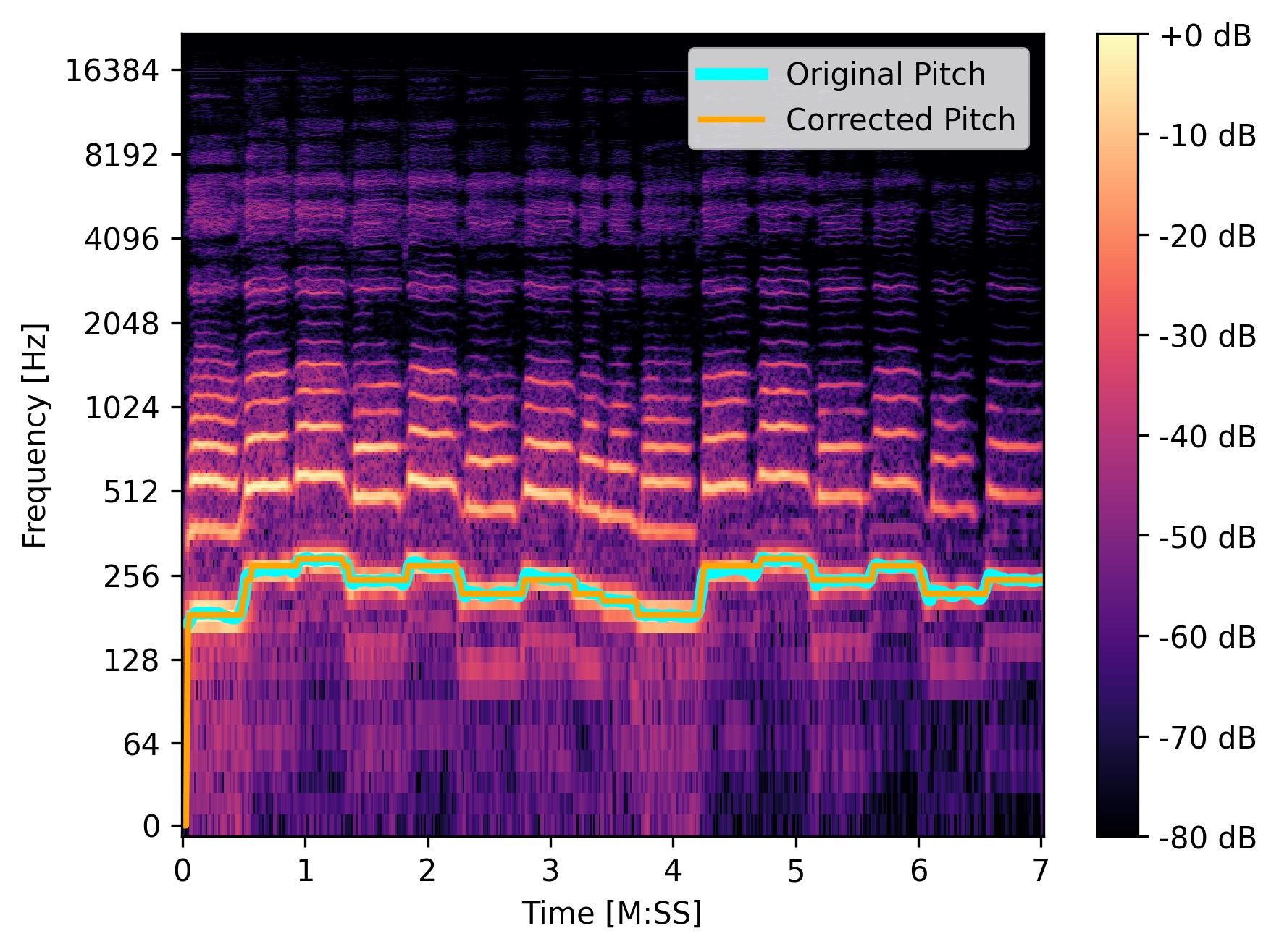
To make it even more clear, here’s a visualization of the original and pitch corrected vocals. Notice how the original is sort of wavey, while the pitch corrected is more stable. This is critical for the model to be able to successfully reproduce the melody.
When you put everything together, the results sound like this:
You can find the code here, or play with it on Hugging Face Spaces. I’ll embed it below for your convenience:
Conclusion
I’m really excited about the future of AI Music for music producers. I hope to keep working in this space and provide music producers tools that they can use to elevate their creativity - NOT replace them. After all, what I’m trying to create here is something I would want to use myself.
If you found this post interesting, please consider supporting me by:
- Giving the model a like on Hugging Face here ❤️
- Giving the source code of singing-songstarter a star ⭐
- Following me on Twitter 🐦
- Following me on GitHub 🐙
- Sharing this post with your friends/enemies 📤
Thanks for reading! 🎶